My last blog post was about my journey towards "getting rid" of Disqus as a comment provider, and moving over to hosting my comments on Github. The blog post was rather light on technical details, so here is the full technical walkthrough with code examples and all.
Since I already explained most of the reasoning and architectural choices in that post I will just go ahead with a step by step of the technical parts I think is interesting. If that means I end up skipping over something important, please let me know in the (Github) comments!
Step 0: Have a Gatsby.js site that pulls it's content from a Drupal site
This tutorial does not cover that, since many people have written such tutorials. As mentioned in my article "Geography in web page performance", I really like this tutorial from Lullabot, and Gatsby.js even has an official page about using Drupal with Gatsby.js.
Step 1: Create a repo to use for comments
The first step was to create an actual repository to act as a placeholder for the comments to be. It should be public, since we want anyone to be able to comment. I opted for the repo https://github.com/eiriksm/eiriksm.dev-comments. To create a repository on GitHub, you need an account, and then just visit https://github.com/new
Step 2: Associate blog posts with issues
The second step is to have a way to indicate which issue is connected to which blog post. Luckily I am still using Drupal, so I can just go ahead and create a field called "Issue id". Then, for each post I write, I create an issue on said repo, and take a note of the issue id. For example, this blog post has a corresponding issue at https://github.com/eiriksm/eiriksm.dev-comments/issues/6, so I just go ahead and write "6" in my issue id field.
Step 3: Fetch all the issues and their comments to Gatsby.js
This is an important part. To be able to render the comments at build time, the most robust approach is to actually "download" the comments and have them available in graphql. To do that you can try to use the source plugin for GitHub, but I opted for getting the relevant issues and comments and creating the source myself. Why, you may ask? Well the main reason is because then I can more easily control how the issue comments are stored, and by extension also store the drupal ID of the node along with the comments.
To achieve this, I went ahead and used the same JSONAPI source as Gatsby will use under the hood, and then I am fetching the issue comment contents of each of the nodes that has an issue ID reference. This will then go into the gatsby-node.js file, to make the data we fetch available to the static rendering. Something along these lines:
exports.sourceNodes = async({ actions, createNodeId, createContentDigest }) => {
const { createNode } = actions
try {
// My build steps knows the basic auth for my API endpoint.
const login = process.env.BASIC_AUTH_USERNAME
const password = process.env.BASIC_AUTH_PASSWORD
// API_URL holds the base URL of my Drupal site. Like so:
// API_URL=https://example.com/
let data = await fetch(process.env.API_URL + 'jsonapi/node/article', {
headers: new fetch.Headers({
"Authorization": `Basic ${new Buffer(`${login}:${password}`).toString('base64')}`
})
})
let json = await data.json()
// Create a job to download each of the corresponding issues and their comments.
let jobs = json.data.map(async (drupalNode) => {
// Here you can see the name of my field. Change this to whatever your field name is.
if (!drupalNode.attributes.field_issue_comment_id) {
return
}
let issueId = drupalNode.attributes.field_issue_comment_id
// Initialize the data we want to store.
let myData = {
drupalId: drupalNode.id,
issueId,
comments: []
}
// As you can see, this is hardcoded to the repo in question. You might want to change this.
let url = `https://api.github.com/repos/eiriksm/eiriksm.dev-comments/issues/${issueId}/comments`
// We need a Github token to make sure we do not hit any rate limiting for anonymous API
// usage.
const githubToken = process.env.GITHUB_TOKEN
let githubData = await fetch(url, {
headers: new fetch.Headers({
// Hardcoded to my own username. This probably will not work for you.
"Authorization": `Basic ${new Buffer(`eiriksm:${githubToken}`).toString('base64')}`
})
})
let githubJson = await githubData.json()
myData.comments = githubJson
// This last part is more or less taken from the API docs for Gatsby.js:
// https://www.gatsbyjs.org/docs/node-apis/#sourceNodes
let nodeMeta = {
id: createNodeId(`github-comments-${myData.drupalId}`),
parent: null,
mediaType: "application/json",
children: [],
internal: {
type: `github__comment`,
content: JSON.stringify(myData)
}
}
let node = Object.assign({}, myData, nodeMeta)
node.internal.contentDigest = createContentDigest(node)
createNode(node)
})
// Run all of the jobs async.
await Promise.all(jobs)
}
catch (err) {
// Make sure we crash if something goes wrong.
throw err
}
}
After we have set this up, we can build the site and start exploring the data in graphql. For example by running npm run develop, and visiting the graphql endpoint in the browser, in my case http://localhost:8000/___graphql:
$ npm run develop
> [email protected] develop /home/eirik/github/eiriksm.dev
> gatsby develop
# ...
# Bunch of output
# ...
⠀
You can now view eiriksm.dev in the browser.
⠀
http://localhost:8000/
⠀
View GraphiQL, an in-browser IDE, to explore your site's data and schema
⠀
http://localhost:8000/___graphql
This way we can now find Github comments with graphql queries, and filter by their Drupal ID. See example animation below, where I find the comments belonging to my blog post "Reflections on my migration journey from Disqus comments".
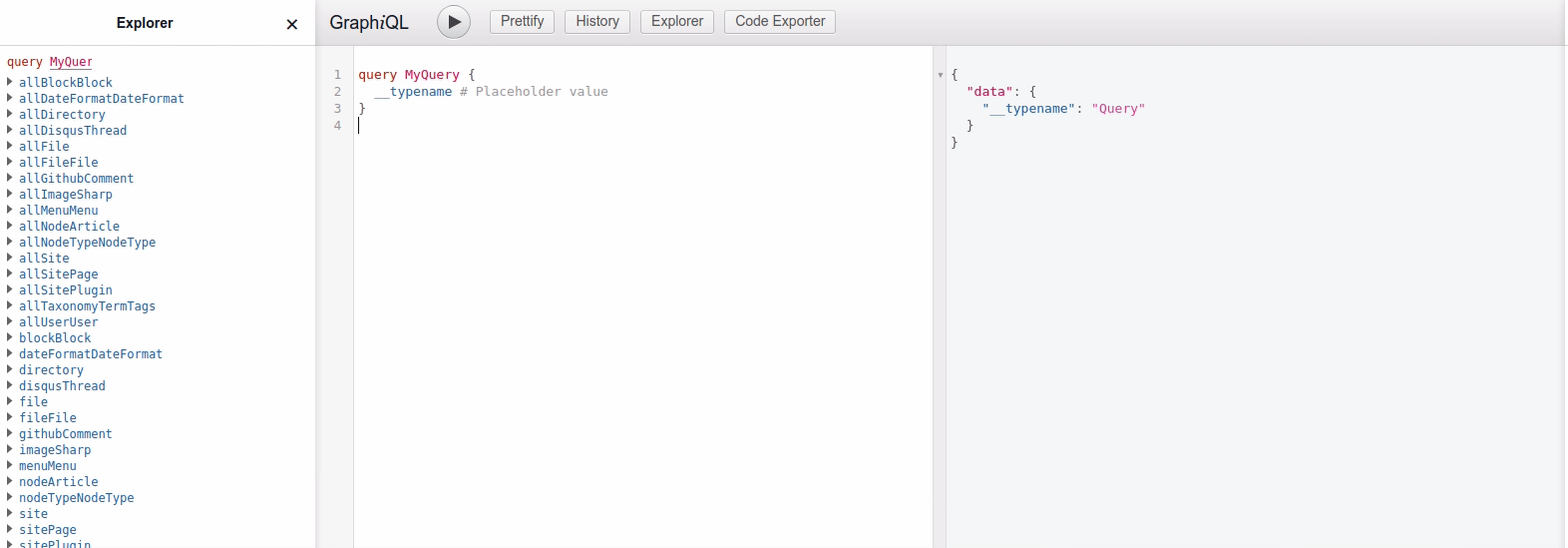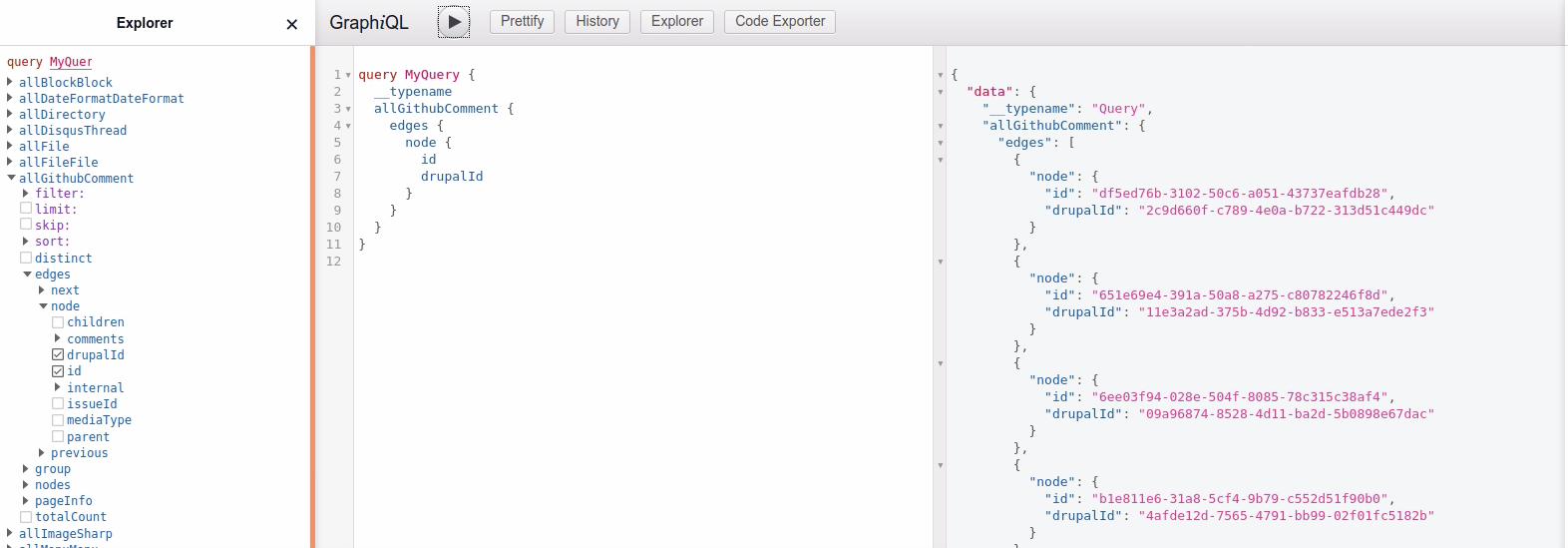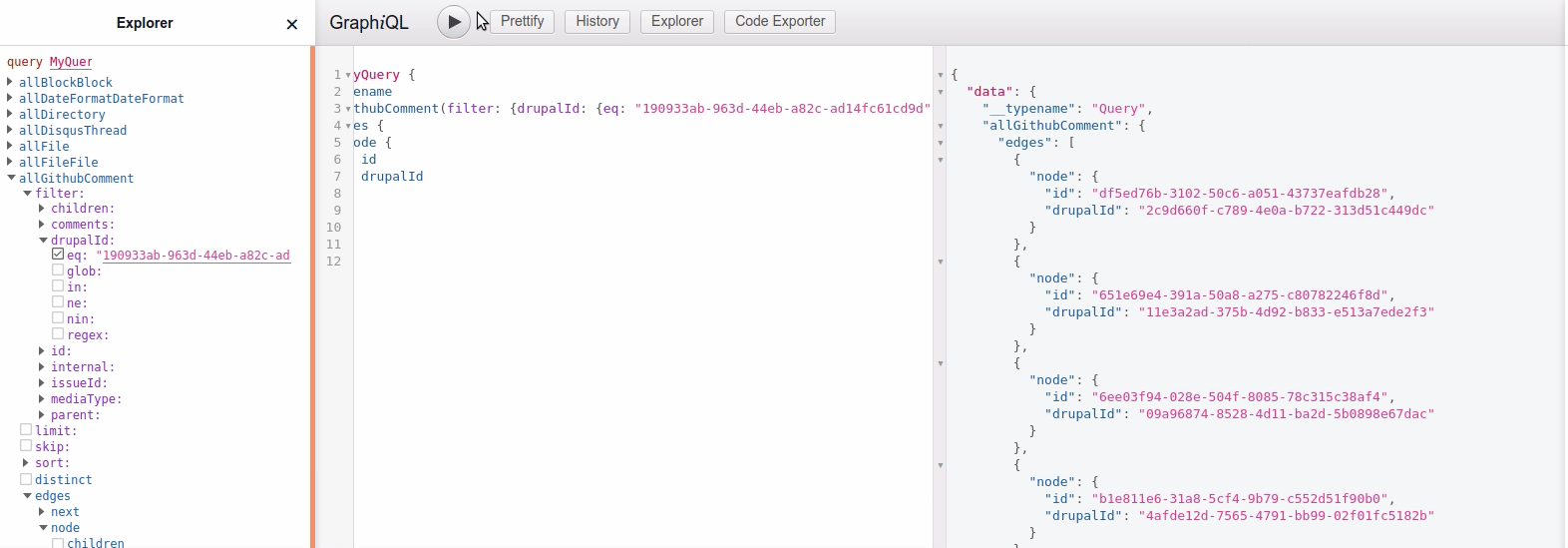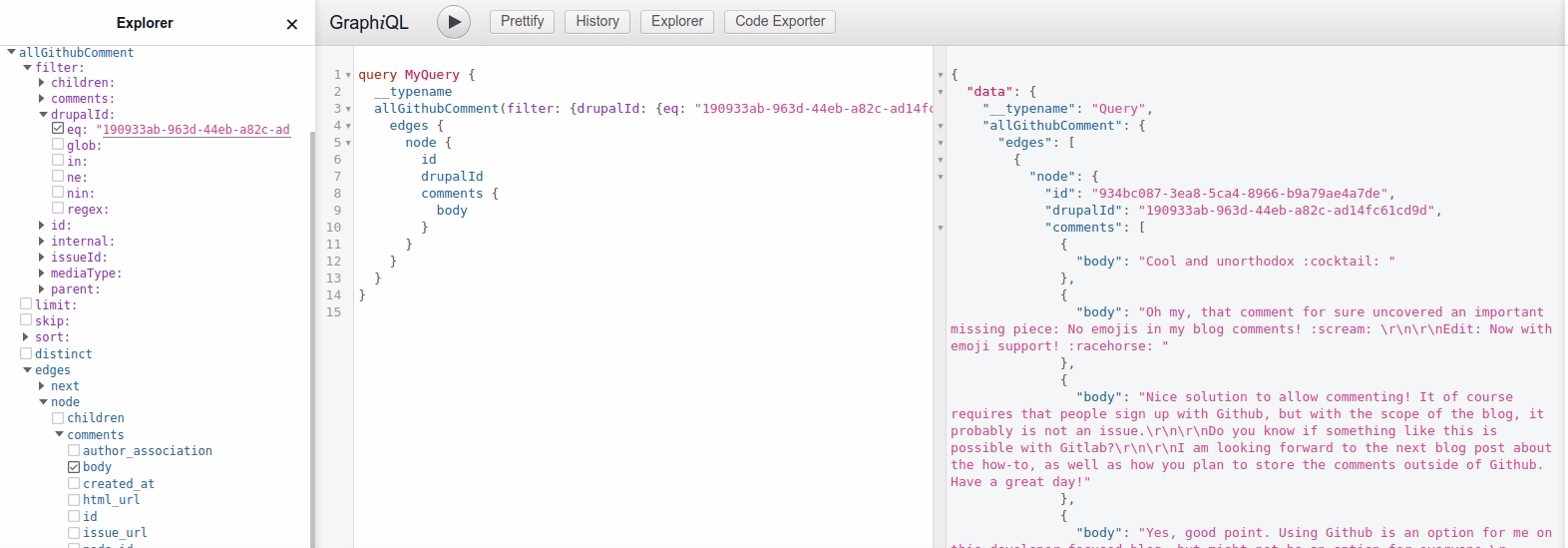
In the end I ended up with the following graphql query, which I then can use in the blogpost component:
allGithubComment(filter: { drupalId: { eq: $drupal_id } }) {
nodes {
drupalId
comments {
body
id
created_at
user {
login
}
}
}
}
This gives me all Github comments that are associated with the Drupal ID of the current page. Convenient.
After this it's only a matter of using this inside of the blog post component. Since this site mix and match comment types a bit (I have a mix of Disqus exported comments and Github comments), it looks something like this:
let data = this.props.data
if (
data.allGithubComment &&
data.allGithubComment.nodes &&
data.allGithubComment.nodes[0] &&
data.allGithubComment.nodes[0].comments
) {
// Do something with the comments.
}
Step 4: Make it possible to fetch the comments client side
This is the part that makes it feel real-time. Since the above code with the graphql storing of comments only runs when I deploy this blog, comments can get quickly outdated. And from a UX perspective, you would want to see your own comment instantly after posting it. This means that even if we could rebuild and deploy every time someone posted a comment, this would not be instant enough to make sure a person actually sees their own comment. Enter client side fetching.
In the blog post component, I also make sure to do another check to github when you are viewing the page in a browser. This is because it is not necessary for the build step to fetch it once again, but I want the user to see the latest updates to the comments. So in the componentDidMount function I have something like this:
componentDidMount() {
if (
typeof window !== `undefined` &&
// Again, only doing this if the article references a github comment id. And again, this
// references the field name, and the field name for me is field_issue_comment_id.
this.props.data.nodeArticle.field_issue_comment_id
) {
// Fetch the latest comments using Githubs open API. This means the person using it will
// use from their own API limit, and I do not have to expose any API keys client side.
window
.fetch(
"https://api.github.com/repos/eiriksm/eiriksm.dev-comments/issues/" +
this.props.data.nodeArticle.field_issue_comment_id +
"/comments"
)
.then(async response => {
let json = await response.json()
// Now we have the comments, do some more work mixing them with the stored ones,
// and render.
})
}
}
Step 5 (bonus): Substitute with Gitlab
Ressa asked in a (Github) comment on my last blogpost about doing this comment setup with Gitlab:
Do you know if something like this is possible with Gitlab?
Fair question. Gitlab is an alternative to Github, but differs in that the software it uses is itself Open Source, and you can self-host your own version of Gitlab. So let's see if we can substitute the moving parts with Gitlab somehow? Well, turns out we can!
The first parts of the project is the same: Create a field, have an account on Gitlab, create a repo for the comments. Then, to source the comment nodes, all I had to change was this:
--- a/gatsby-node.js
+++ b/gatsby-node.js
@@ -125,15 +125,25 @@ exports.sourceNodes = async({ actions, createNodeId, createContentDigest }) => {
issueId,
comments: []
}
- let url = `https://api.github.com/repos/eiriksm/eiriksm.dev-comments/issues/${issueId}/comments`
- const githubToken = process.env.GITHUB_TOKEN
+ let url = `https://gitlab.com/api/v4/projects/eiriksm%2Feiriksm.dev-comments/issues/${issueId}/notes`
+ const githubToken = process.env.GITLAB_TOKEN
let githubData = await fetch(url, {
headers: new fetch.Headers({
- "Authorization": `Basic ${new Buffer(`eiriksm:${githubToken}`).toString('base64')}`
+ "PRIVATE-TOKEN": githubToken
})
})
let githubJson = await githubData.json()
+ if (!githubJson[0]) {
+ return
+ }
myData.comments = githubJson
+ // Normalize it slightly.
+ myData.comments = myData.comments.map(comment => {
+ comment.user = {
+ login: comment.author.username
+ }
+ return comment
+ })
let nodeMeta = {
id: createNodeId(`github-comments-${myData.drupalId}`),
parent: null,
As you might see, I took a shortcut and re-used some variables, meaning the graphql is querying against GithubComment. Which is a bad name for a bunch of Gitlab comments. But I think cleaning those things up would be an exercise for the reader. The last part with client side updates was not possible to do in a similar way. The API for that requires authenticating the request. Much like the above code from sourcing the comments. But while the sourcing happens at build time, client side updates happens in the browser. Which would mean that for this to work, there would be a secret token in your JavaScript for everyone to see. So that is not a good option. But it is indeed theoretically possible, and could for example be achieved with a small proxy server, or serverless function.
The even cooler part is that the exact same code also works for a self-hosted Gitlab instance. So you can indeed run open source software and own your own data with this approach. That being said, not using a server was one of the requirements for me, so that would defeat the purpose. In such a way, one might as well use Drupal as a headless comment storage.
I would still like to finish with it all working in Gitlab too though. In an animated gif, as I always end my posts. Even though you are not allowed to test it yourself (since, you know, the token is exposed in the JavaScript), I think it serves as an illustration. And feel free to (Github) comment if you have any questions or feel I left something out.
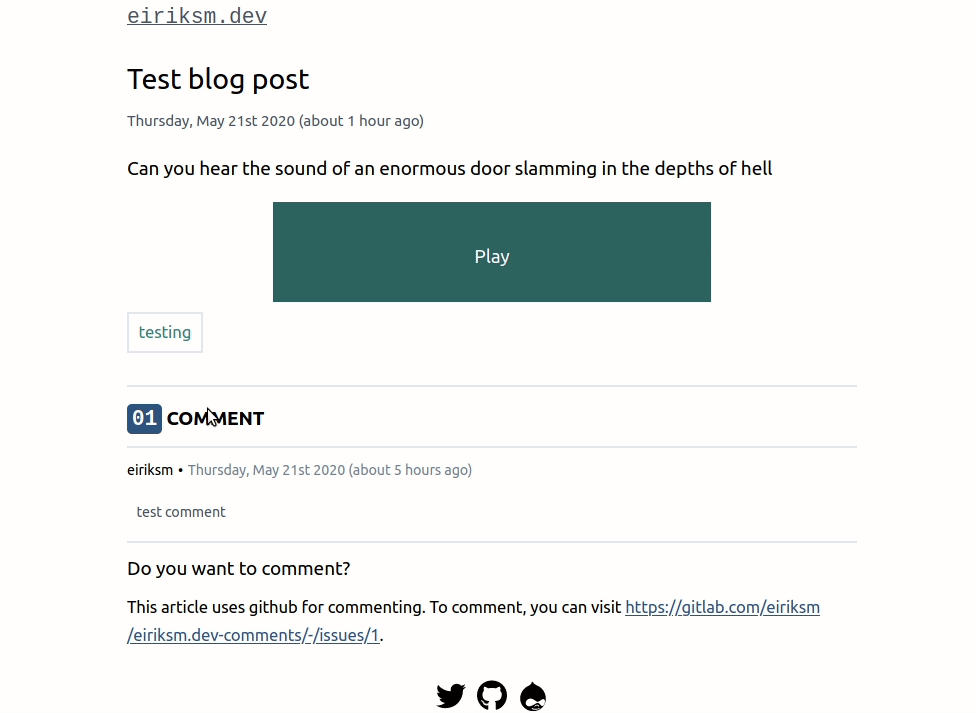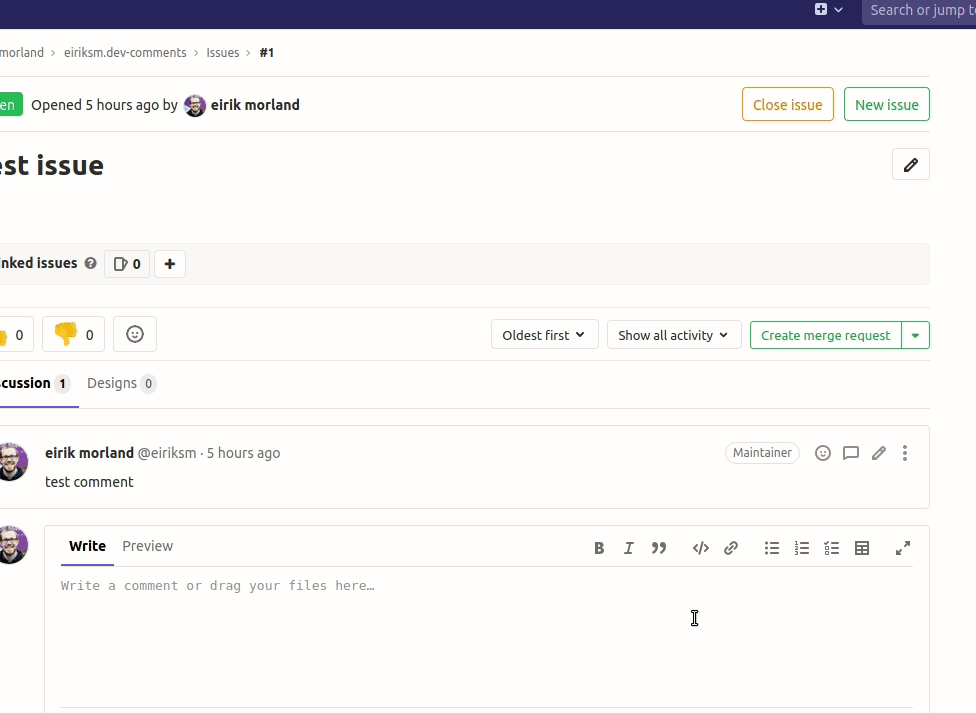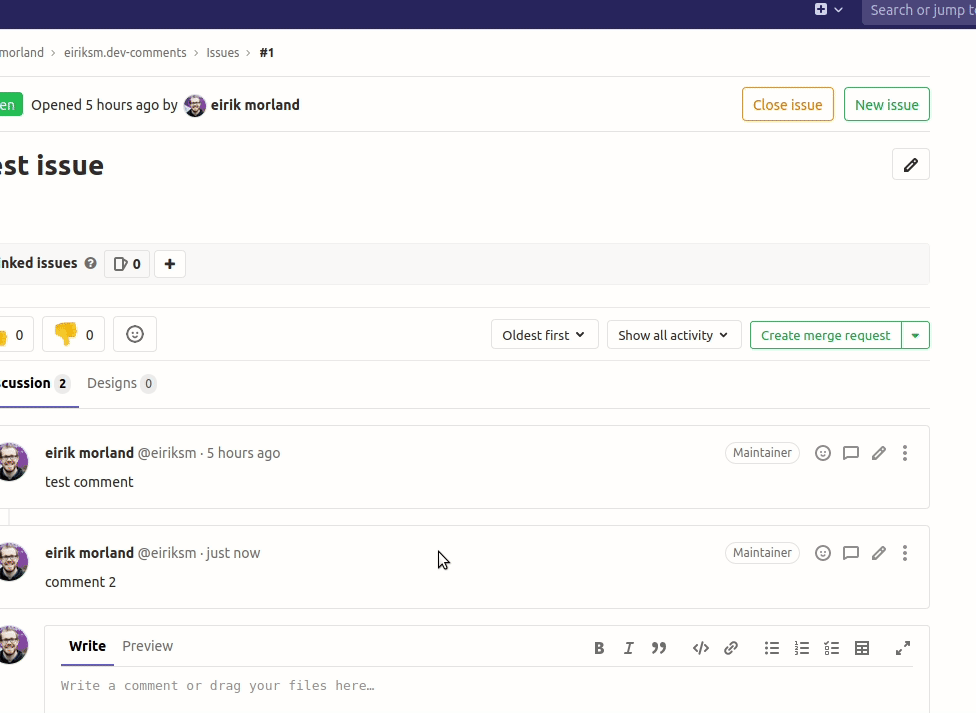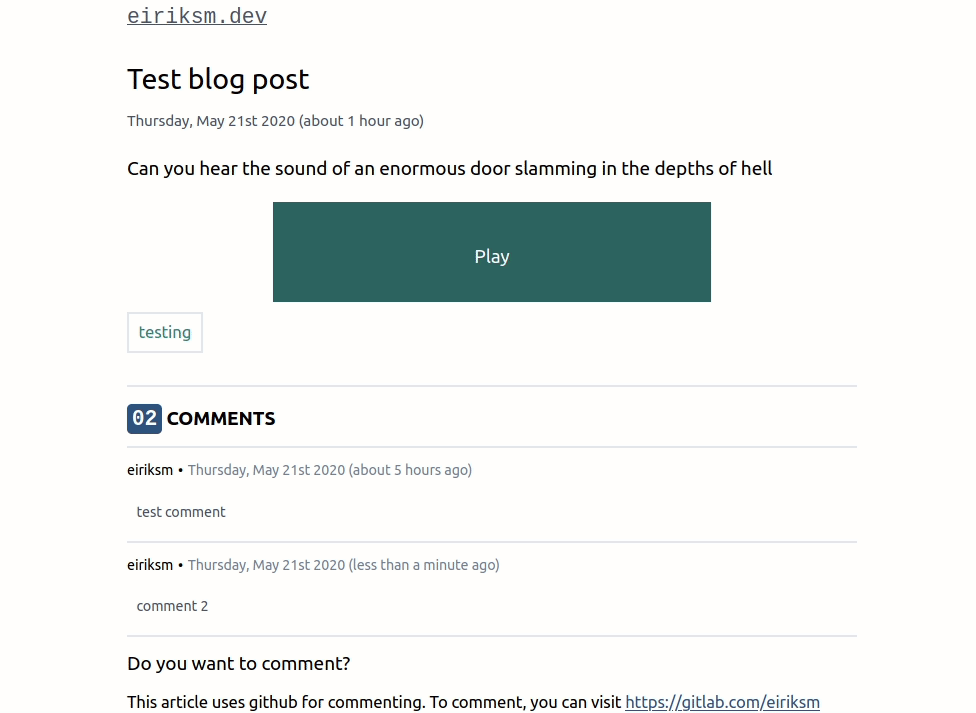
gitressa•Sunday, May 24th 2020 (about 5 years ago)
dasjo•Sunday, May 24th 2020 (about 5 years ago)
ElijahLynn•Thursday, May 28th 2020 (about 5 years ago)
ElijahLynn•Thursday, May 28th 2020 (about 5 years ago)
I think a solution needs to be worked out so that a normal refresh shows new comments.
ElijahLynn•Thursday, May 28th 2020 (about 5 years ago)
eiriksm•Friday, May 29th 2020 (about 5 years ago)
Thanks again for commenting! 🤓
arafalov•Wednesday, Aug 12th 2020 (almost 5 years ago)
eiriksm•Wednesday, Aug 12th 2020 (almost 5 years ago)
Thanks for commenting!
Do you want to comment?
This article uses github for commenting. To comment, you can visit https://github.com/eiriksm/eiriksm.dev-comments/issues/6.